It's been a constant pain in the proverbial to use this Thinkpad R50e, running Ubuntu 9.04, with and without an external keyboard.
It spends much of its life fixed to a desk with an external USB keyboard, connected via a four port USB hub/speaker combination. In this manner, the [NumLock] key needs to be pressed ( on the external keyboard ) for the numeric keys to be usable.
However, when the hub etc. is unplugged e.g. when the laptop goes on the road, the [NumLock] light stays illuminated, meaning that the numeric keys on the Thinkpad's own keypad become activated, preventing half the keyboard from being used for its proper purpose e.g. the U key becomes a 4, the K key becomes a 2 etc. etc. etc.
The problem is that it's not easy to disable [NumLock] from within the Gnome X11 environment - switching to another virtual terminal using [Ctrl][Alt][F1] etc. sometimes works, but that's not a particularly elegant solution.
There are probably better ways, but a Google search found me NumlockX
which does the job far more elegantly.
I installed it as follows: -
sudo apt-get install numlockx
It has three parameters, easily displayed using the command numlockx -? which are: -
on - turns NumLock on in X ( default )
off - turns NumLock off in X
toggle - toggles the NumLock on and off in X
However, I didn't want to have to open a shell merely to do this, so I wrote a simple script: -
#!/bin/bash
numlockx off
saved as numlock.sh which, having set as executable ( chmod +x ) in my user's home directory, I then created a desktop shortcut ( via a Custom Application Launcher ) to it.
I placed this shortcut on the bottom panel, alongside Firefox, Thunderbird, Open Office, Skype etc. and now have a simple way of toggling the NumLock off.
If I wanted to, I could have amended the script to read: -
#!/bin/bash
numlockx toggle
to that I could change the state on AND off, at the click of a mouse button.
Simple ....
Thursday 31 December 2009
Problem with CUPS and Samba on Ubuntu 9.04 ( Jaunty Jalope )
Had an interesting problem with my 10 year old HP PSC500 printer, whilst trying to print a PDF file from Document Viewer.
Not having been aware of changing anything since this last worked, I was assuming that my Ubuntu box's configuration hadn't changed drastically, and I'd already checked the power and parallel ( old skool ) printer cables.
The error message that kept popping up was: -
"Failed To Print Document, Too Many Failed Attempts"
which wasn't particularly meaningful.
I started and stopped the printer via the CUPS web UI at: -
http://localhost:631/printers/
but to no avail.
I'd also tried starting and stopping CUPS, via the shell commands: -
sudo service cups restart
When I checked the CUPS error log /var/logs/cups/error.log, I saw the following errors, which appeared relevant: -
E [31/Dec/2009:13:56:27 +0000] cupsdReadClient: 17 IPP Read Error!
E [31/Dec/2009:13:58:13 +0000] cupsdReadClient: 17 IPP Read Error!
E [31/Dec/2009:14:00:01 +0000] cupsdReadClient: 17 IPP Read Error!
A quick Google search suggested that the problem might be with Samba (!) rather than CUPS, even though I'm printing directly from the application on the PC to which the printer is connected.
Be that as it may, I tried restarting Samba: -
sudo service samba restart
and tried to reprint the offending document.
Lo and behold, the printer started printing and we're back in the game ....
Weird but true ...
Not having been aware of changing anything since this last worked, I was assuming that my Ubuntu box's configuration hadn't changed drastically, and I'd already checked the power and parallel ( old skool ) printer cables.
The error message that kept popping up was: -
"Failed To Print Document, Too Many Failed Attempts"
which wasn't particularly meaningful.
I started and stopped the printer via the CUPS web UI at: -
http://localhost:631/printers/
but to no avail.
I'd also tried starting and stopping CUPS, via the shell commands: -
sudo service cups restart
When I checked the CUPS error log /var/logs/cups/error.log, I saw the following errors, which appeared relevant: -
E [31/Dec/2009:13:56:27 +0000] cupsdReadClient: 17 IPP Read Error!
E [31/Dec/2009:13:58:13 +0000] cupsdReadClient: 17 IPP Read Error!
E [31/Dec/2009:14:00:01 +0000] cupsdReadClient: 17 IPP Read Error!
A quick Google search suggested that the problem might be with Samba (!) rather than CUPS, even though I'm printing directly from the application on the PC to which the printer is connected.
Be that as it may, I tried restarting Samba: -
sudo service samba restart
and tried to reprint the offending document.
Lo and behold, the printer started printing and we're back in the game ....
Weird but true ...
IBM WebSphere eXtreme Scale 6 by Anthony Chaves - my thoughts thus far
As mentioned previously, I'm working my way through Anthony Chaves' book on WebSphere eXtreme Scale. It's a very good book, but it is as much aimed at an application developer as at an infrastructure architect like me.
In my simple world, the main benefit of a data grid is that vast amounts of data can be held in memory, spread across as many processors as is necessary to handle the performance and storage requirements. This means that a data-centric application, such as that used in the banking and financial sectors, can access data far more quickly. The book has a great chart that compares data access times from the CPU registers ( ~ 1 nanosecond ) through main memory ( ~ 150 nanoseconds ) to secondary storage cache aka disk cache ( ~ 50 microseconds ) to secondary storage itself ( ~ 12 milliseconds ).
To quote from the book itself "... Accessing data on a hard drive platter is one million times slower than accessing that same data in main memory and one billion times slower than accessing that data in a register..."
The chapter goes on to compare the relative cost and capacity of CPU registers against disk storage - this makes perfect sense; I'm typing this on a Macbook Pro which has 6 MB of Level 2 cache ( access time is around 20 nanoseconds ), 4 GB of main memory ( access time is around 150 nanoseconds ) and 320 GB of hard disk ( access time is around 12 milliseconds ). I recently bought a 320 GB SATA hard disk for 30 pounds, and a 1 TB SATA hard disk for 60 pounds, but I'm guessing that it'd cost me a heck of a lot more to add more main memory, and I've got little or no chance of adding extra L2 cache, unless Apple happens to provide a quad core CPU with 16 MB as an upgrade - not likely :-)
The net benefit of the datagrid approach is that a programmer can ensure that data is held as close as possible to the processor cores, and not need to rely upon costly ( in performance terms ) database interactions - the Java Enterprise Edition (JEE) approach of database access is immensely powerful in terms of allowing a programmer to interact with a relational database without knowing or caring on what platform it runs - this abstraction via the Java Naming and Directory Interface (JNDI) and Java Database Connectivity (JDBC) APIs, via statement and connection pools etc. is very very useful, but does add latency to each and every database interaction. Caching data in memory helps, but only for read operations. Similarly, object locking takes a similar amount of time - each time I want to update a database record, I have to go to and from the database application itself.
Whilst not solving every problem, datagrids can help to mitigate against this, and the API appears immensely flexible in terms of read/write, locking, caching etc.
As a non-developer, I'm not going to see all of the benefits, but it's definitely worth considering, especially where performance and scalability are crucial requirements.
In terms of the book, Mr Chaves clearly knows his subject, and writes extremely well - it should be noted that he does jump into Java code quite quickly, with the first snippets of code appearing on page 17. It's in the later chapters that he goes into the architecture and the cost vs. benefit analysis of the datagrid methodology.
The book is aimed at the WebSphere eXtreme Scale product, and Mr Chaves even goes through the process of obtaining and installing the product, but the concepts are appropriate to any similar datagrid product.
I've got a lot more book to work through, but I'm impressed thus far - again, as an architect rather than a developer, with 10 years of Java experience behind me ( even at the basic J2EE / JEE level with servlets, portlets, JSPs, entity beans, session beans etc. ), the book is eminently readable, and I'd be happy to recommend it to anyone. The author's style is friendly without being patronising - it's not "Datagrids for Dummies" but that's probably a good thing :-)
Wednesday 30 December 2009
Integrating IBM Lotus Connections 2.5 with other applications
I may well have blogged about this article previously, but it's definitely worthy of a read, and quite appropriate to me at this time.
Summary: This article takes a deep dive into IBM Lotus Connections 2.5 Application Programming Interfaces (APIs). Through practical examples, we explain how to work with the Connections 2.5 APIs and how to use them to integrate Lotus Connections into other applications.
Wednesday 23 December 2009
Sametime 8.5 - Should You Wait and Other Burning Questions?
An extremely useful posting from Gabriella Davis at Turtle Partnership, that's definitely worth a read if you're considering the newly-released Sametime 8.5 product set: -
<snip>
As most of you know by now, Sametime 8.5 and all its new components shipped yesterday. In summary Sametime 8.5 offers you:
- Community Server on a Domino platform (supported for Domino 8.5 but otherwise little changed from ST8.0.2)
- Meeting Server on WAS 7.0 (replaces existing Domino based scheduled meetings with persistent, always available, meeting 'spaces')
- Media Server on WAS 7.0 (audio and video services for the Meeting Server)
- Proxy Server on WAS 7.0 (no download Ajax browser client for IM, customisable / brandable via CSS)
The whole environment is then managed by the Sametime System Console on WAS 7.0.
</snip>
Determining the best IBM Lotus Web Content Management delivery option for your needs
One of my ISSL colleagues shared this via Twitter: -
Summary
There are various content delivery options available in IBM Lotus Web Content Management (hereafter called "Web Content Management"), and choosing the one that's right for you can improve the current performance and future scalability of your deployed environment. This article explains the available rendering options and how to choose the best one for your Web sites.
Thursday 17 December 2009
Hmmm, fancy some XPages development training in London in February ?
If so, go here: -
and sign up - for a measly 130 of your fine English pounds :-)
Wednesday 16 December 2009
New Redpiece - IBM Lotus Domino Integration using IBM Tivoli Directory Integrator
Am using TDI more and more now on Lotus Connections projects, and am starting to see it in the context of Domino engagements as well.
One of my current projects is to use TDI to pull Domino users out of a group and propagate them into the Profiles database that is a key part of Lotus Connections.
I haven't yet read this redpiece, but it comes from a good source - one of the authors, Eddie Hartman, is one of the most knowledgeable TDI people I've ever "met".
Here's the abstract: -
In this IBM Redpaper publication we take you step-by-step through a series of integration scenarios to help you start building your own solutions with IBM Tivoli Directory Integrator. Once you have mastered some basic skills you will be wiring your IBM Lotus Domino applications (both the shrink-wrapped and home-grown varieties) more tightly into your infrastructure, and you will also be sharing data between IBM Lotus Domino and other systems more simply and easily that you probably thought was possible.
and here's the URL: -
Whilst we're on the subject, here's two more useful TDI-related URLs: -
IBM Tivoli Directory Integrator Users Group
http://www.tdi-users.org/twiki/bin/view/Integrator/WebHome
Google Groups TDI Forum
http://groups.google.com/group/ibm.software.network.directory-integrator/topics?lnk=srg
http://www.tdi-users.org/twiki/bin/view/Integrator/WebHome
Google Groups TDI Forum
http://groups.google.com/group/ibm.software.network.directory-integrator/topics?lnk=srg
Thursday 10 December 2009
Shelling out on Ubuntu 9.10 ( Karmic Koala )
Having not really had a chance to do much with Ubuntu recently ( mainly since I crossed over to the Cupertino side with the absolutely awesome Apple Macbook Pro and OSX ), I've got back into the game recently, as I build a play/dev. box on my trusty old 2007-AE7 Thinkpad T60p.
I installed Ubuntu 9.10 Karmic Koala on the beast the other week, and have most recently installed: -
Lotus Mobile Connect 6.1.3.0-1.3
DB2 UDB 9.1.0.5
Lotus Domino 8.5.1
Tivoli Directory Integrator 6.1.1 FP7
( appreciating that all/most of the above are completely UNSUPPORTED by IBM on Ubuntu )
The reason for this is that I'm trying to crack a problem with TDI whereby I want to bring users who are members of a Domino group into Lotus Connections 2.5 via TDI. This doesn't work out of the box, mainly due to the way that Domino groups work when exposed via LDAP.
Therefore, I needed to create a custom TDI Assembly Line, which I've now done. My AL populates a file called collect.dns.
Once the AL has done the job of pulling the users from the group, I then need it to populate those same users into Connections, via the underlying Profiles database.
Rather than reinventing the wheel, I need my AL to call one of the Connections Wizard's underlying scripts - populate_from_dn_file.sh - which takes the contents of the aforementioned collect.dns file and posts it into the Profiles DB.
In order to have my AL call the existing script, I needed to use the Command Line Collector.
However, when I tried to validate that the populate_from_dn_file.sh script worked ( outside TDI ), I got the following error: -
./tdienv.sh: 4: [[: not found
./tdienv.sh: 7: [[: not found
./tdienv.sh: 10: [[: not found
./populate_from_dn_file.sh: 10: [[: not found
./populate_from_dn_file.sh: 14: [[: not found
./populate_from_dn_file.sh: 18: [[: not found
After a quick Google, I discovered that the problem is that the TDI scripts use the SH shell which, for some weird reason on Ubuntu, is actually linked to the /bin/dash shell.
Obvious, heh ? NOT !
The solution ?
sudo mv /bin/sh /bin/sh.bak
sudo ln -s /bin/bash /bin/sh
sudo ln -s /bin/bash /bin/sh
In essence, we backup the old version of /bin/sh and replace it with a version that links to /bin/bash.
Nice one !
I'll post more on the TDI hacking once I've got it working properly, and tested :-)
Thursday 3 December 2009
WebSphere Portlet Factory 6.1.5 - My First Failure .... and success
Having recently installed WebSphere Portal Express 6.1.5, I went one step further on Wednesday and installed WebSphere Portlet Factory Designer 6.1.5 onto the same Red Hat Enterprise Linux VMware image.
a) Sun JRE 1.6.0_17-bo4 - jre-6u17-linux-i586-rpm.bin - from here http://javadl.sun.com/webapps/download/AutoDL?BundleId=35674

Hmmmmm, things did not go quite as smoothly as I'd expected.
I downloaded/installed in this order: -
a) Sun JRE 1.6.0_17-bo4 - jre-6u17-linux-i586-rpm.bin - from here http://javadl.sun.com/webapps/download/AutoDL?BundleId=35674
b) Eclipse Galileo - eclipse-jee-galileo-SR1-linux-gtk.tar - from here http://www.eclipse.org/downloads/download.php?file=/technology/epp/downloads/release/galileo/SR1/eclipse-jee-galileo-SR1-macosx-cocoa.tar.gz
c) WebSphere Portlet Factory Designer 6.1.5 - CZ7RYML.zip
In case it's relevant, I "merely" installed Eclipse by expanding the TAR file into /opt/eclipse.
So far so good.
Whilst creating a WPF project, I'm prompted to create a new Server Configuration for the deployment of the project to WebSphere Application Server / WebSphere Portal.
Since 6.1 was released, WPFD can connect to WAS via SOAP as well as the more traditional HTTP method. I think I'm right in saying that this allows for remote deployment of WARs ( where WPFD is on one machine and WAS/WP is on another ) so it's a good feature to have.
Having taken the defaults for the WAS/WP 6.1 configuration: -

I clicked the "Test Connection" button ..... and saw .....
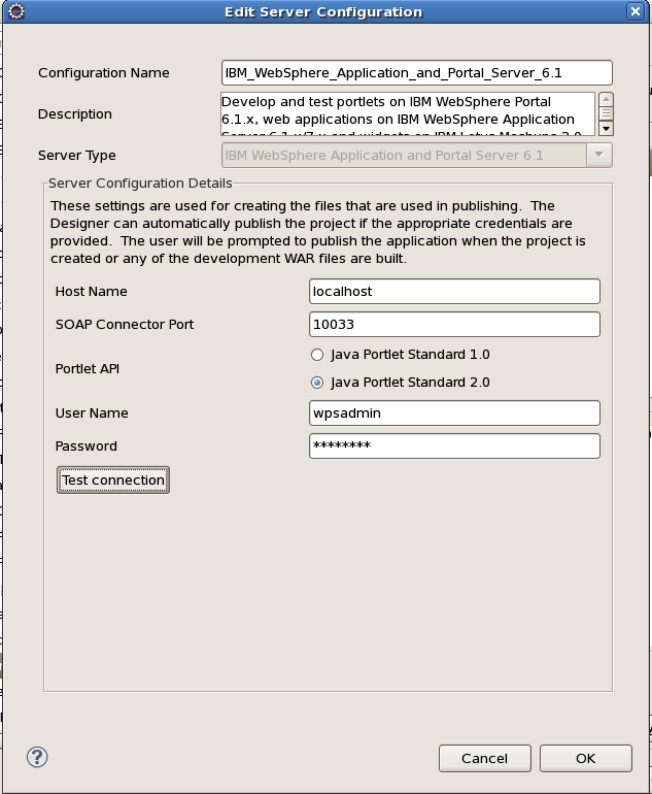
I clicked the "Test Connection" button ..... and saw .....

Check your Host and SOAP Connector port inputs. To verify your SOAP Connector port, go to the WebSphere Admin Console, select Application Servers > YOUR_SERVER > Ports and use the SOAP_CONNECTOR_ADDRESS
I followed the advice in the dialogue box and checked that the WebSphere_Portal instance of WAS was running, and the SOAP_CONNECTOR_ADDRESS was indeed 10033. I even proved it using the WSAdmin script as follows: -
/opt/IBM/WebSphere/PortalExpress/AppServer/bin/wsadmin.sh -port 10033 -user wpsadmin -password passw0rd -lang jython
By this time I was getting very desperate, and was using netstat -aon | grep 10033 to prove that the port was available, and even checked that the firewall - IPTables - was NOT running.
I then tried starting WPF in debug mode ( by running /opt/eclipse/eclipse -debug ) and then saw the following exceptions when I clicked the "Test Connection" button: -
INFO: ssl.disable.url.hostname.verification.CWPKI0027I com.ibm.websphere.management.exception.ConnectorException: ADMC0053E: The system cannot create a SOAP connector to connect to host localhost at port 10033 with SOAP connector security enabled.
Caused by: [SOAPException: faultCode=SOAP-ENV:Client; msg=Error opening socket: java.net.SocketException: java.lang.ClassNotFoundException: com.ibm.websphere.ssl.protocol.SSLSocketFactory; targetException=java.lang.IllegalArgumentException: Error opening socket: java.net.SocketException: java.lang.ClassNotFoundException: com.ibm.websphere.ssl.protocol.SSLSocketFactory]
com.bowstreet.designer.deploy.DeploymentException: An error occured trying to create the admin client. Check your Server Configuration inputs, and make sure your server is running.
Caused by: [SOAPException: faultCode=SOAP-ENV:Client; msg=Error opening socket: java.net.SocketException: java.lang.ClassNotFoundException: com.ibm.websphere.ssl.protocol.SSLSocketFactory; targetException=java.lang.IllegalArgumentException: Error opening socket: java.net.SocketException: java.lang.ClassNotFoundException: com.ibm.websphere.ssl.protocol.SSLSocketFactory]
com.bowstreet.designer.deploy.DeploymentException: An error occured trying to create the admin client. Check your Server Configuration inputs, and make sure your server is running.
At this point, I decided to call in the heavy mob - thanks to two of the smart people in the US, Jonathan B and Kevin T, I was able to crack it.
The ClassNotFound exception against com.ibm.websphere.ssl.protocol.SSLSocketFactory helped indicate the problem - Kevin advised me to check that the class did exist in the right place: -
/opt/IBM/WebSphere/PortletFactory/Designer/eclipse/plugins/com.bowstreet.designer.JMXConnection_6.1.5/WAS6.1/com.ibm.ws.security.crypto_6.1.0.jar
and then suggested that the problem MIGHT be a JRE issue; apparently the com.ibm.websphere.ssl.protocol.SSLSocketFactory class has a dependancy on the IBM Java Runtime Environment.
I proved this by changing my environment to use the IBM JRE that's packaged with WebSphere Application Server instead of the Sun JRE, by use of the setupCmdLine.sh, as follows: -
Before changing the environment
$ java -version
java -version
java version "1.6.0_17"
Java(TM) SE Runtime Environment (build 1.6.0_17-b04)
Java HotSpot(TM) Client VM (build 14.3-b01, mixed mode, sharing)
Change the environment
. /opt/IBM/WebSphere/PortalExpress/AppServer/profiles/wp_profile/bin/setupCmdLine.sh
( noting the leading DOT SPACE )
After changing the environment
$ java -version
java version "1.5.0"
Java(TM) 2 Runtime Environment, Standard Edition (build pxi32devifx-20090811 (SR10 +IZ56666+IZ56751))
IBM J9 VM (build 2.3, J2RE 1.5.0 IBM J9 2.3 Linux x86-32 j9vmxi3223-20090707 (JIT enabled)
J9VM - 20090706_38445_lHdSMr
JIT - 20090623_1334_r8
GC - 200906_09)
JCL - 20090811
Java(TM) 2 Runtime Environment, Standard Edition (build pxi32devifx-20090811 (SR10 +IZ56666+IZ56751))
IBM J9 VM (build 2.3, J2RE 1.5.0 IBM J9 2.3 Linux x86-32 j9vmxi3223-20090707 (JIT enabled)
J9VM - 20090706_38445_lHdSMr
JIT - 20090623_1334_r8
GC - 200906_09)
JCL - 20090811
Having done this, I was able to restart Designer, and deploy my project using SOAP.
In short, if you see similar exceptions re SSLSocketFactory, check that you're not running the Sun JRE.
Tuesday 1 December 2009
Oooh, shiny, WebSphere Portal and WebSphere Process Server together ...
as per this developerWorks article: -
"...The guide contains the steps for building a two-node portal cluster running on WebSphere Application Server 6.1.0.15 and integrating this environment with WebSphere Process Server 6.1.0.1 in the same WAS cell, including the transfer of Portal's Derby database to an external database server..."
This is something I really need to read ( I feel the need, the need to read or, perhaps, the need to speed read ).
Subscribe to:
Posts (Atom)
Visual Studio Code - Wow 🙀
Why did I not know that I can merely hit [cmd] [p] to bring up a search box allowing me to search my project e.g. a repo cloned from GitHub...
